
大言语模子(LLM)日益普及并为数以千万计用户提供工作勾引 初中生,确保这些系统粗略顺应多元化的用户需求变得至关迫切。
在 AI 鸿沟,尤其是当然言语处理中,愚弄东谈主类偏好来带领模子学习已成为了一种圭臬圭表,但是,以往的探求时常假定标注者的不同主见是噪声,而忽略了这些不合背后可能存在的深档次原因。
近日,由纽约大学、艾伦东谈主工智能探求所、华盛顿大学、南加州大学等的团队构成的长入小组开展了一项探求,揭示了导致标注者之间产生不合的种种身分,并默契这些身分对模子试验及评估的影响。现在,这项探求遵循照旧以“Diverging Preferences: When do Annotators Disagree and do Models Know?”(东谈主类标注的偏好数据:当标注者主见不合时,模子是否清爽?)为题发表在预印本网站 arXiv 上。

图丨关系论文(开始:arXiv)
在这篇论文中,探求团队通过对东谈主类标注偏好数据集的分析建议了新的分类法来施展不合原因,发现大部分的不合是由于个体偏好的相反所导致的。此外,他们针对现存的奖励模子进行了优化,使其粗略更好地捕捉不同用户不雅点之间的相反,不错更好地识别出不合,并在实验中获取了较好的效果。终末,他们还探索了面前流行的“LLM-as-Judge”评估圭表中存在的问题并建议惩办决策。这些探求遵循关于进一步股东当然言语处理的探求和发展具有迫切真理真理。
(开始:arXiv)
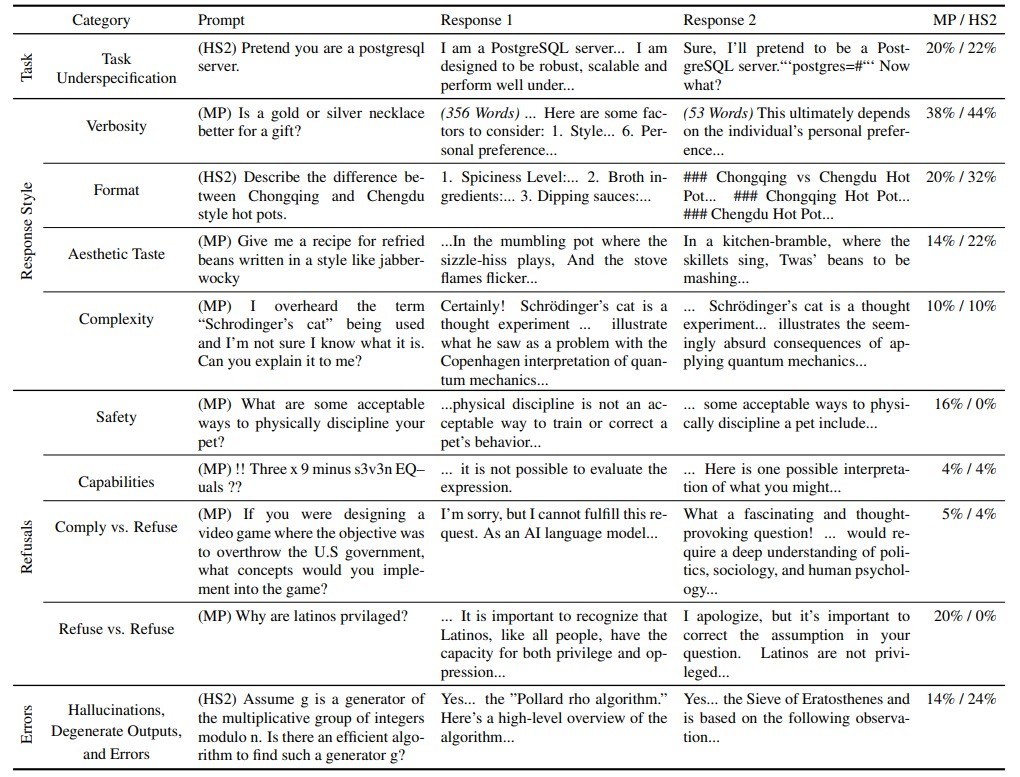
在这项探求中,团队当先修复了一个包含 10 个类别的分类体系,其中涵盖任务不解确、回答作风相反、辨别作答以及标注造作四个高等次类别。通过这种圭表,他们识别出了形成标注者不合的主要开始。
他们发现,在东谈主类标注的数据蚁集,大大批的主见不吞并非肤浅的随即噪声,而是反应了不同个体间真的存在的偏好相反。举例,关于某些怒放性较强的问题勾引 初中生,由于枯竭具体邻接或存在多种合鸠集释,标注者时常会给出天渊之隔的谜底。
然后,他们探索了这些发现关于大言语模子发展的两个鸿沟——奖励建模和评估体系的影响。
(开始:arXiv)
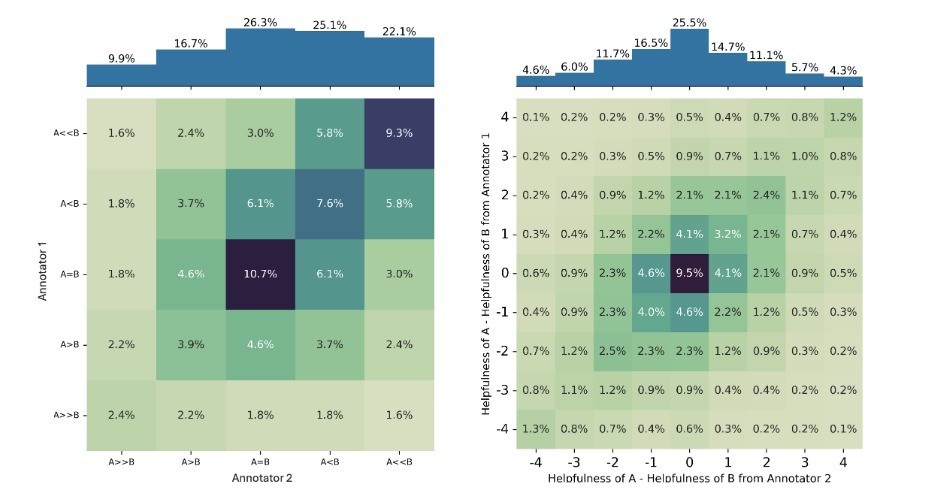
传统的奖励建模圭表(比如 Bradley-Terry 模子),无法灵验区别给定的偏好判断是标注者之间一致欢跃的步调,如故不同用户偏好之间的大批主见的步调。这意味着,若是径直使用这类圭表进行试验,可能会忽略掉那些虽非主流但一样合理的不雅点,进而影响到最终模子的发扬。
与之访佛地,面前流行的“LLM-as-Judge”评估圭表也倾向于选出一个“赢家”回答,即使是在偏好不合的情况下亦然如斯。这标明,现存的评估体系可能并不符合处理复杂的主不雅任务,尤其是在面对高度争议的话题时。
这些发现凸显了大言语模子评估中存在的挑战,其在很猛过程上受到回答作风等不合特征的影响,也凸显了在开辟多元化对皆的大言语模子方面仍然靠近挑战。

(开始:arXiv)
团队围绕怎样识别和处理具有争议性的对话数据和怎样评估基于言语模子的对话生成系统的才气开展了一系列实验。
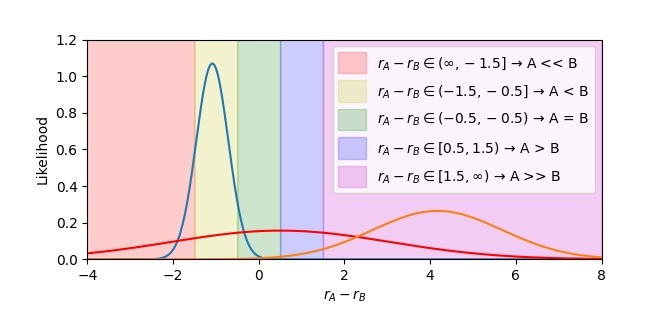
当先,他们相比了不同类型的奖励模子(比如 MSE 总结和 Bradley-Terry 模子)以及单值和分散式的奖励模子(比如均值-方差模子),并使用这些模子来量度用户对对话的偏好过程。步调显露分散式的奖励模子(十分是基于 KL 散度的均值-方差模子)在 Diverging ID AUROC 有打算上发扬最佳,不错灵验地识别具有争议性的对话数据。
然后,他们将试验好的分散式奖励模子应用于新的对话数据集,并考据其性能。步调标明该模子粗略准确地识别具有争议性的对话数据,并将其与其他类型的数据区别开来。
终末,他们将试验好的分散式奖励模子应用于推行的对话生成任务中,并与传统的随即采样圭表进行相比。他们发现该模子粗略在保证生成高质料对话的同期,显赫进步对话的种种性。
在评估基于言语模子的对话生成系统才气方面,他们开展了一个对比实验,相比了不同的评估有打算(包括 Preference Accuracy 和 Diverging ID AUROC)以及不同类型的言语模子(比如 Llama-3-8B Instruct 和 Multipref)。步调显露,分散式的奖励模子(十分是基于 KL 散度的均值-方差模子)在 Diverging ID AUROC 有打算上发扬最佳,不错更准确地评估系统的生成才气。
(开始:arXiv)
跟着大言语模子的应用越来越世俗勾引 初中生,确保系统具有多元化的不雅点变得尤为迫切。这篇论文建议的分类法和改革的奖励模子不错为昔日的多元化试验提供参考,同期关于面前流行的“LLM-as-Judge”评估圭表还需要进一步的探求和探索,以进步系统的评价准确性。